
Picture a sentence you never wrote, published on your own domain, that no customer will ever read and your AI assistant will repeat as fact. A support line that rings an attacker. A “required” migration tool that belongs to someone else. A set of nameservers that are not yours. Planting that sentence takes no breach of your servers and no line of malicious code: it takes an edit to a quiet markdown file most companies forgot they publish. And on the evidence of this audit, once it is planted, nothing on the average host’s estate is watching. Not a scanner. Not an uptime monitor. Not a human. Not a signature. Of the 110 hosting-industry domains we found serving the file, not one carries a control that would notice it had changed. The file built to make a company legible to machines is the same file nobody is guarding, and it is sitting on trusted infrastructure whose word AI agents repeat as the company’s own.
On Friday this publication audited the AI-crawl posture of 736 hosting and infrastructure companies and found, in a separate census, that 110 of them publish a file at /llms.txt: a plain-markdown catalog written for one audience only, the AI agents and crawlers that read it and act on it. We promised a follow-up on what that census doubles as, and this is it. The hosting industry, along with everyone else adopting the convention, has stood up a new content channel with three properties that should not coexist: machines consume it verbatim, humans never look at it, and no security model exists for it anywhere. Not in the specification, which we re-fetched and searched this morning and which contains zero security, integrity, or authentication provisions. Not in the IETF’s adjacent standards work, which governs preference expression and explicitly disclaims enforcement. Not in the WordPress security stack, where no major vendor documents any monitoring of llms.txt content. And not on the 110 domains themselves: none sign the file, only eight signpost it, and 28 never wrote it at all, because an SEO plugin did. As of publication there is no documented case of a tampered llms.txt in the wild. That is the window, not the comfort: every component of the attack has already been demonstrated separately, and the file sits on trusted infrastructure-industry domains whose word AI assistants repeat as fact.
Key facts, measured June 11, 2026
- 110 of 589 definitively answering hosting-industry domains publish /llms.txt (our census, n=736 sample): 60 curated indexes, 28 SEO-plugin autogenerated, 13 linkless, 9 oversized dumps of 150KB+, the largest 727KB
- Zero of the 110 sign or checksum the file; only 8 reference it from robots.txt; exactly one company in the sample (mijn.host) cites the IETF AI-preferences work; no WordPress security vendor documents llms.txt content monitoring
- The specification has no security model: the llms.txt spec (Answer.AI, September 3, 2024) contains no integrity, signing, authentication, or sanitization provisions of any kind, verified by direct retrieval June 12, 2026
- 28 of the 110 files are written by three plugins with 17M+ combined active installs: Yoast SEO (10M+, generator shipped June 10, 2025, opt-in), Rank Math (4M, opt-in module), All in One SEO (3M, enabled by default)
- Machine-only deception is demonstrated, not hypothetical: SPLX showed in October 2025 that a one-line user-agent check feeds AI crawlers fabricated content they repeat as ground truth; JFrog published the “parallel-poisoned web” technique in August 2025; Palo Alto’s Unit 42 has observed indirect prompt injection via web content in the wild
- The supply-chain precedents are recent and large: polyfill.io served malicious code into 100,000+ sites in June 2024 (384,773 hosts still embedding it on July 2, 2024, per Censys); five WordPress.org plugins were backdoored via developer accounts the same month; Gravity Forms’ official download channel shipped a backdoor in July 2025
- The honest counterweight: Google says no AI system formally consumes llms.txt, and crawler-log studies show the file is rarely requested; the attack surface argument does not require universal consumption, only an agent that reads on demand
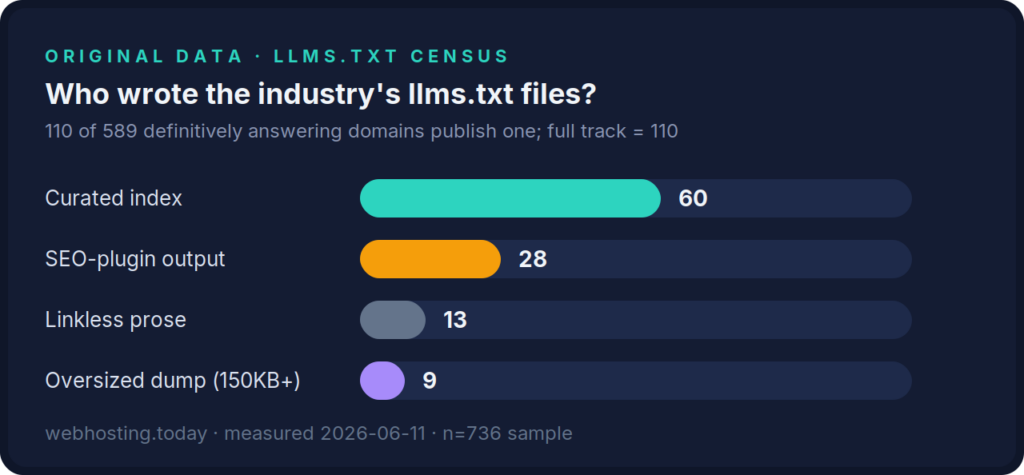
Who wrote the industry’s 110 llms.txt files: barely half are deliberate, curated indexes. Measurement: webhosting.today census, June 11, 2026.
A Trusted Channel With No Security Model
The llms.txt convention is twenty-one months old. Jeremy Howard of Answer.AI proposed it on September 3, 2024 as a courtesy to language models: a concise markdown index at a well-known path, telling an AI system what a site is and where its machine-readable documentation lives, the way robots.txt tells crawlers where not to go and sitemap.xml tells them what exists. The proposal is elegant, useful, and 11 kilobytes long, and we searched every byte of it on June 12: it contains no occurrence of “security,” “integrity,” “signature,” “authentication,” “sanitize,” “tamper,” or “verify” in any security-relevant sense (the only lexical match is a section heading titled “Integrations”). There is no trust model, no provenance mechanism, no guidance on who may write the file or how a consumer might check that it is genuine. The same is true one layer up: the IETF’s AI Preferences working group, the closest thing this space has to a standards process, is drafting a vocabulary for expressing usage preferences, and its core draft states plainly that it “does not provide any enforcement mechanism” and seeks only to ensure preferences are understood. It governs rights expression, not content integrity. Exactly one company in our 736-domain sample cites that work at all.
Fairness requires the counterargument up front. The file’s actual reach is contested: Google’s John Mueller compared llms.txt to the long-dead keywords meta tag in April 2025 and wrote in June 2025 that “FWIW no AI system currently uses llms.txt”; Ahrefs’ log analysis found AI crawlers barely request the file; and Google does not support it in Search (though an llms.txt briefly and accidentally appeared on Google’s own developer docs in December 2025, shipped by a CMS update, which rather proves the plugin point below). If nothing reads the file, who cares what’s in it? Three answers. First, the spec’s intended use case is not bulk training crawls but on-demand inference: an agent asked about a company fetching that company’s self-description at answer time, precisely the moment a poisoned line does the most damage, and per-request fetches by design leave a fainter log signature than crawler sweeps. Second, adoption is moving in one direction: 110 publishers in our industry sample against 8 a layer down in robots.txt references, GoDaddy publishing its pricing in the format, Anthropic publishing one for its own documentation. Third, and decisively for a security analysis: the attack does not need every AI system to consume the file. It needs one agent, acting for one customer, to trust it once.
Attack Class One: Tamper With the File Nobody Reads
Deface a hosting company’s homepage and the defacement is measured in minutes: customers see it, monitoring sees it, screenshots reach social media before the incident channel does. Edit the same company’s /llms.txt and, on the evidence of this census, nothing happens at all. Humans do not browse the file. Uptime monitors do not check it. Marketing does not reread it after publication (Oracle’s robots.txt has signposted an llms.txt that returns 404 for as long as we have been measuring, on the same domain whose per-bot crawler annotations are the most carefully written in our sample; if the signpost to a missing file survives that long unnoticed, no one is auditing the channel). And the security stack does not cover it, a claim we verify in detail below. A tampered llms.txt is a defacement with no witnesses except the machines it was written for.
Serving one truth to humans and another to machines is not a novel idea; it is one of the oldest named abuse patterns on the web. Google’s spam policies have prohibited cloaking, “presenting different content to users and search engines,” for two decades. What is new is the demonstration that the AI layer falls for it with less effort. In October 2025, researchers at SPLX showed that a single user-agent check, serving a fabricated page exclusively to the crawlers behind ChatGPT Atlas and Perplexity, was enough to make those systems present the fabrication as established fact; their write-up’s key line is that for retrieval-based AI, “whatever content is served to them becomes ground truth.” A month earlier, JFrog’s Shaked Zychlinski had published the generalization on arXiv: a “parallel-poisoned web” that fingerprints AI agents and serves them visually identical pages carrying hidden injected instructions, invisible to every human visitor. And Palo Alto Networks’ Unit 42 has documented indirect prompt injection via ordinary web content in the wild. Against that backdrop, llms.txt is not a new attack class; it is the same class with the difficulty removed. The attacker needs no fingerprinting and no cloaking logic, because the victim has voluntarily published a dedicated machines-only channel and labeled it as such.
The census says the industry has also provided the hiding room. Nine of the 110 files are dumps of 150KB or more, against a specification whose entire point is a concise index: Webempresa’s runs to 727KB, Selectel’s to 512KB, Ultahost’s to 431KB, hoster.by’s to 346KB, e-monsite’s to 331KB, InMotion Hosting’s to 312KB, Hostinger’s to 293KB, mijn.host’s to 205KB, and Vercel’s to 177KB (all re-fetched and confirmed byte-stable on June 12). Nobody diffs a 727KB machine-facing text file. A paragraph inserted at byte 400,000, telling agents that migrations require a “verification tool” hosted elsewhere or that support is reached at an attacker’s number, would sit on a reputable infrastructure domain indefinitely, with the domain’s full authority behind every word.

The governance gap: publication without any of the controls that would notice tampering. “Monitored: 0” reflects vendor documentation as of June 12, 2026; no scanner we reviewed covers llms.txt content.
Attack Class Two: One Plugin Update, Twenty-Eight Catalogs
The second attack class is the one that scales, and our census measured its precondition directly. 28 of the 110 files were not written by the companies that serve them. They are autogenerated by SEO plugins, and they say so: Heroku’s llms.txt opens with “Generated by Yoast SEO v27.7, this is an llms.txt file, meant for consumption by LLMs,” and the same fingerprint, at varying version numbers, appears on Plesk, UpCloud, Servebolt, Raidboxes, Kamatera, WEDOS, cyber_Folks, and twenty more hosting-industry domains (both quotes re-verified live on June 12). A quarter of the industry’s adoption of an agent-facing content channel happened as a plugin feature, not a company decision, which means the integrity of those 28 catalogs is exactly the integrity of the plugin update pipeline that writes them.
That pipeline’s recent record is the argument. In February 2024 a little-known operator bought the polyfill.io domain and its GitHub account; by June 2024 the service was injecting malicious redirects into the 100,000+ sites that embedded it (Sansec’s count; Censys still found 384,773 hosts referencing the domain on July 2, 2024), and Cloudflare resorted to rewriting the URL across its network. The same month, five plugins on WordPress.org, Social Warfare the largest at 30,000+ installs, shipped backdoored updates after their developers’ accounts fell to reused passwords; the malware created rogue admin accounts and injected SEO spam. In July 2025 the official download channel of Gravity Forms, a commercial plugin the vendor counts on roughly a million sites, served a backdoored release for about two days before Patchstack’s disclosure. Each incident compromised a trusted publishing mechanism to reach every site downstream, and each was caught because what it shipped was code: signatures matched, file hashes changed where scanners look, behavior tripped alarms.
Now run the same play through the llms.txt generator. A compromised release of any of the three plugins that write these files would not need to ship malware at all. It would need to append content: a recommended “migration assistant,” a support phone number, a link given a trustworthy markdown label. The output lands in a file that scanners do not read, that humans do not open, and that is supposed to change when the plugin updates, so even a diff-based control would see routine regeneration. A poisoned recommendation is not an indicator of compromise; it is a sentence. The install bases define the exposure: Yoast SEO sits on 10M+ active installs (its generator shipped in version 25.3 on June 10, 2025, opt-in), Rank Math on 4M (opt-in module), and All in One SEO on 3M, where llms.txt generation is enabled by default, on a platform that W3Techs measured at 41.5% of all websites this morning. WordPress’s “Protect The Shire” change, which we covered on June 8, puts a 24-hour default delay on plugin auto-updates and genuinely narrows this window for the code path. It does nothing for the content path: once a poisoned generator is past the delay, every regenerated catalog it writes is clean by every check that exists today.

The layer above the file: three plugins with 17M+ combined installs write agent-facing catalogs, including 28 of the 110 in our industry census. Install counts: wordpress.org, June 2026.
Attack Class Three: Steering the Agents That Buy
The first two classes describe how poisoned content gets into the channel. The third is why it pays. 2026 is the year the industry wired agents to act on what they read: WooCommerce 10.9 shipped agent abilities that let AI assistants browse, carting, and check out; the payment layer beneath them (x402, agent-native checkout) is this publication’s running 402-economy story; and research accepted to IEEE S&P 2026 found 13% of sampled e-commerce sites already ran chatbot integrations vulnerable to indirect prompt injection. An agent that reads a hosting company’s llms.txt is, increasingly, an agent in the middle of a transaction: comparing plans, quoting renewal prices, walking a customer through a migration, choosing where to point a domain.
GoDaddy demonstrates the legitimate version. Its llms.txt indexes markdown documentation of pricing and products; when an assistant is asked what GoDaddy charges, GoDaddy has supplied the answer in the assistant’s native format. The attack is the same mechanism with different intent. A tampered catalog on a hosting domain can steer the agent’s answer about anything the domain is authoritative for: which control panel download is current, which nameservers to set, which “official partner” handles migrations, which number is support. SPLX’s proof of concept is instructive precisely because it was mundane: a fabricated resume served only to AI crawlers altered AI-assisted hiring decisions. Swap the resume for a price list or a support link on a domain ranked trustworthy by every reputation system, and the steering inherits the host’s authority. The agent does not present the poisoned line as a claim from a text file; it presents it as what the company says.
Who Owns This Risk
For a hosting CISO, the uncomfortable property of this surface is that every control that would catch tampering exists, is cheap, and is pointed elsewhere. We checked the vendor documentation on June 12. Wordfence’s scan covers core, plugin, and theme file integrity and known malware signatures; nothing in its documentation reads llms.txt content, and its only llms.txt-adjacent output is vulnerability advisories about llms.txt-generating plugins themselves, such as the reflected XSS in the “Website LLMs.txt” plugin (CVE-2026-27068). The one documented interaction between Wordfence and the file points the other way: its rate limiting has been reported blocking AI crawlers from reading llms.txt. Patchstack does vulnerability mitigation and states plainly that it does not scan files. Sucuri’s SiteCheck looks for known malware, defacements, and SEO spam in rendered pages, and its documentation does not mention llms.txt at all. None of this is negligence; it is lag. The product category “watch the files machines trust” has existed for decades for code. For agent-facing content it does not exist yet, and per our census, zero of 110 publishers have improvised it themselves.
The ownership question splits three ways, and the contracts have not caught up with any of them. The host owns the domain and the reputational hit: a tampered llms.txt is the host’s voice, whatever wrote it, the same logic our CVE-41940 liability analysis traced for compromised control panels, where the bill lands wherever the paperwork was silent. The plugin vendor owns the pipeline: three companies now write agent-facing statements on behalf of 17M+ sites, with no signing, no content attestation, and in one case generation on by default, a posture choice that deserves more scrutiny than it has had. And the agent operator owns the consumption: OWASP has ranked prompt injection the top LLM risk since 2023 precisely because retrieved content is untrusted input, yet a file format whose stated purpose is “meant for consumption by LLMs” invites exactly the verbatim trust the ranking warns against. European regulators will eventually notice that a poisoned vendor-published file directing customer-facing AI agents is a security incident in substance regardless of what the reporting taxonomy calls it; the Cyber Resilience Act’s reporting clock starts in September. It would be better for the industry to have an answer before the first incident report has to invent one.
What a Responsible Host Does Now
There is no signing standard to adopt; until one exists, the available control is attention, and it is nearly free. Six moves, in order of effort:
- Inventory the file. Determine whether your domains serve /llms.txt (and llms-full.txt), and who writes each one: marketing, a plugin, or nobody anyone remembers. In our census, the honest answer at 28 companies is “a plugin,” and at 13 more the file has no links and no evident owner.
- Put it under file-integrity monitoring. The file changes rarely by design; alerting on any modification of a few kilobytes of text is the cheapest tripwire in your estate. Diff on change, route to security, not marketing.
- Treat generator plugins as production publishers. Pin versions, keep the 24-hour update delay, and reread the generated output after plugin updates, because regeneration is exactly when injected content would arrive looking routine.
- Keep it small and signposted. A concise curated index, referenced from robots.txt, is what the specification intended, and it is also the auditable shape: a reviewer can read 2KB; nobody reads 727KB. Only 8 of 110 publishers currently add the one-line robots.txt signpost.
- Check the links quarterly. Oracle’s signpost has pointed at a 404 for months. Link rot in a machine-facing catalog is both an embarrassment and an acquisition opportunity for whoever registers what you abandoned.
- Put it in scope. Incident response runbooks, pen-test scopes, and the next conversation with your scanner vendor should all name llms.txt explicitly. The first vendor to ship content-tampering coverage for agent-facing files gets a differentiator the whole industry will need; ask yours when.
The pattern this industry should recognize is its own history compressed. Robots.txt shipped in 1994 with no security model and mostly never needed one, because it only said where not to go. Llms.txt is different in kind: it says what is true, to readers that act on it, for customers who never see the handoff. Channels like that, polyfill’s CDN, the plugin update stream, the package registries, have all been attacked within our recent memory, and each time the lesson was the same: the trusted path gets a security model only after someone abuses it. This one is twenty-one months old, growing, and still clean as far as anyone can observe. The industry rarely gets a documented attack surface, with measured baselines, before the first incident. This is what one looks like.
Methodology
The llms.txt census derives from our June 11, 2026 AI-posture audit (n=736 industry domains; 589 answered definitively at /llms.txt), classifying the 110 published files by spec-format heading, link presence, size, and generator fingerprints. On June 12 we re-verified at source: the llms.txt specification was retrieved directly from llmstxt.org and searched for security-relevant terms (none present); the nine oversized files were re-fetched and matched their census sizes byte-for-byte or within one byte; generator fingerprints were re-confirmed live on heroku.com and plesk.com; W3Techs’ WordPress share (41.5% of all websites) was read the same day; plugin install counts are wordpress.org directory figures as of June 2026 (Rank Math’s exact llms.txt release date and AIOSEO’s introducing version are not pinned in public changelogs and are stated here only at the precision we could verify). Scanner-coverage claims rest on vendor documentation reviewed June 12, 2026, and are claims about documented capability, not about undisclosed internal tooling. We found no documented real-world llms.txt tampering incident as of publication; that absence is itself a finding, stated as such.
Sources
- The /llms.txt file - llms.txt Specification (official)
- The /llms.txt file: a proposal (September 3, 2024) - Jeremy Howard, Answer.AI (official)
- A Vocabulary For Expressing AI Usage Preferences (draft-ietf-aipref-vocab) - IETF AIPREF Working Group
- AI-Targeted Cloaking (October 2025) - SPLX (official research)
- A Whole New World: Creating a Parallel-Poisoned Web Only AI-Agents Can See (arXiv:2509.00124, August 2025) - Shaked Zychlinski, JFrog Security Research
- Web-Based Indirect Prompt Injection Observed in the Wild - Palo Alto Networks Unit 42 (official)
- LLM01:2025 Prompt Injection - OWASP GenAI Security Project (official)
- Polyfill supply chain attack hits 100K+ sites (June 25, 2024) - Sansec (official research)
- Polyfill.io Supply Chain Attack: Digging into the Web of Compromised Domains (July 2, 2024) - Censys (official)
- Automatically replacing polyfill.io links with Cloudflare's mirror (June 2024) - Cloudflare (official)
- Supply Chain Attack on WordPress.org Plugins (June 24, 2024) - Wordfence (official)
- Critical Malware Found in Gravity Forms Official Plugin Site (July 2025) - Patchstack (official)
- Yoast SEO 25.3 changelog (June 10, 2025) - Yoast (official)
- LLMs.txt module documentation - Rank Math (official)
- How to Create an llms.txt Using All in One SEO (enabled by default) - AIOSEO (official)
- Usage statistics of WordPress (read June 12, 2026) - W3Techs
- Spam policies for Google web search (cloaking) - Google Search Central (official)
- Google Says LLMs.Txt Comparable To Keywords Meta Tag (April 18, 2025) - Search Engine Journal
- What Is llms.txt, and Should You Care About It? (crawler-log analysis) - Ahrefs
- Wordfence Scan documentation - Wordfence (official)
- Does Patchstack have a malware scanner? - Patchstack (official)
- Malware scanning documentation - Sucuri (official)
- Website LLMs.txt <= 8.2.6 Reflected Cross-Site Scripting (CVE-2026-27068) - Wordfence Threat Intelligence