
The hosting industry has spent 2026 selling the agentic web. Per-crawler controls for 20 million customers. Agent identity on DNS. “Agent-ready” conference keynotes. AI plugins force-installed onto a million sites. The sales pitch is everywhere.
So we asked the question nobody had measured: what does the industry’s own machine-readable AI posture look like? Not what hosts sell to customers, but what their own front doors declare.
On June 11, 2026, we retrieved and analyzed the robots.txt files of 736 companies: the global hosting industry, plus the cloud, CDN, registrar, PaaS, and control-panel layers around it. For each one we checked three things: named AI crawlers, Content-Signal declarations, and llms.txt references.
The headline is a near-total silence. Of the 573 companies whose files our agents could read and verify:
- Only 47 name even one AI crawler
- Only 25 declare a Content-Signal
- Only 8 reference an llms.txt
- 58 in total (10%) show any AI-era signal at all
And the silence concentrates exactly where the marketing is loudest: the mass-market hosting giants.
But the audit’s real value is in the configured minority. The fifty-eight companies that have answered the question did so in five distinctly different ways: welcome, refusal, differentiation, catalog, and outsourcing. That spread of strategies, mapped below, is the closest thing the industry has to a working manual, written by its own most deliberate actors.
Hosting M&A Consultation
Get one-on-one advice on maximizing your hosting company’s valuation and navigating the sale process.
First, in Plain English: What Are We Even Measuring?
Most of this article turns on four things that live in the plumbing of almost every website. If you have never heard of them, here is the whole idea in under a minute. None of it needs a technical background.
- robots.txt. A tiny text file that nearly every website keeps at one fixed address (for example, yoursite.com/robots.txt). It is the web’s oldest set of house rules: it tells automated visitors, called bots or crawlers, which parts of the site they are welcome to read. It has existed since 1994, and anyone can open one in a browser right now.
- AI crawlers. The newest kind of bot. Companies like OpenAI, Google, and Anthropic send out crawlers (with names like GPTBot, Google-Extended, and ClaudeBot) that read web pages either to train their AI models or to answer a user’s question on the spot. A website can name these crawlers in its robots.txt and decide, one by one, whether to let them in.
- Content-Signal. A single newer line a site can add to its robots.txt, introduced in September 2025. Instead of a blunt yes or no, it states intent in three parts: may this page appear in search results, may an AI read it to answer a question, and may an AI use it for training. It is how a site says “quote me, but do not train on me.”
- llms.txt. A separate file (yoursite.com/llms.txt) that does the opposite job to robots.txt. Rather than keeping machines out, it hands them a clean, plain-text summary of what the site offers, written for AI assistants. Think of it as a cheat sheet a company writes so that when someone asks an AI “what does this company sell, and what does it charge,” the assistant has a tidy, accurate answer to read.
Put together, these four things are how a website states, in a language machines can read, what it wants AI systems to do with its content. This audit did the thing nobody had done at scale: it went and checked what the hosting industry’s own websites actually say. Everything below is what we found.
Key facts, audit of June 11, 2026 (n=736; 573 readable, 646 with a verified result)
- 47 of 573 (8%) name any AI crawler in robots.txt; 25 (4%) declare a Content-Signal; 8 reference llms.txt; union of any AI-era signal: 58 of 573 (10%): 90% express no AI policy whatsoever
- The llms.txt census (separate dimension): 110 of 589 definitively answering domains publish a file at /llms.txt, fourteen times the robots-referenced count; 60 curated, 28 SEO-plugin autogenerated, 13 linkless, 9 oversized 150KB+ dumps; Oracle’s robots.txt points to an llms.txt that 404s
- The mass-market hosting giants are silent: Bluehost, HostGator, Hostinger, IONOS, Namecheap, SiteGround, OVHcloud, DreamHost, Contabo, Netcup, Strato, one.com, HostPapa, Wix, WordPress.com, no AI-specific rules of any kind
- The hyperscalers too: AWS, Azure, and Google Cloud’s marketing domains carry no AI-crawler policy, the most articulate robots.txt among the giant clouds belongs to Oracle, with per-bot annotations
- Declared posture skews 5:1 against training: twenty-one Content-Signals say ai-train=no (Render, Vercel, InterServer, eukhost, pair, mijn.host, and the Cloudflare-managed cohort); four say yes (Cloudflare, Liquid Web, Hover, Kinsta)
- The outsourcing signal: fifteen brands on all six inhabited continents (A2, FastComet, TMDHosting, Webcentral, UK2, MochaHost, Doteasy, HostingRaja, ColombiaHosting, id.ie, Kebir Host, mi.com.co, Nasani, Libya’s Libyan Spider, and Germany’s NetHit) carry the same Cloudflare-managed policy with an Article 4 EU 2019/790 rights reservation, eight byte-identical: policy by infrastructure, not by decision
- Graded A to F: 22 A, 36 B, 515 D, 73 F; fifteen of the twenty-two A grades sit on Cloudflare-managed files; only 7 of the first-pass 35 verifiably had any signal a year ago, and 11 giants are verified unchanged since at least June 2025
- Seventy-three companies serve no robots.txt at all, including Hetzner, Afrihost, Netlify, fly.io, WHMCS, and four domain registries (DENIC, auDA, TWNIC, and Poland’s NASK); 90 more were unmeasurable: 28 hard blocks, 27 challenge pages served with a 200 status, 31 unreachable after repeated attempts, 3 other failures, 1 inconsistent responder
- The registry layer, measured properly: of 33 ccTLD and gTLD registries audited, 26 grade D, four serve no robots.txt at all, and the only machine-readable AI postures in the world’s naming layer belong to Southeast Asia: .ph references llms.txt from robots, .th publishes one
- The crawler league: GPTBot is named in 81% of the 48 files that name anything; Bytespider is the only crawler named mostly to be banned
- No segment leads: CDNs 2/5, clouds 2/6, PaaS 2/7, managed WordPress 2/10, mass-market top twenty 2/20: configuration does not rise with technical sophistication
- Fifty companies serve a literally empty robots.txt, and the IETF’s AI-preferences draft is implemented by exactly one company in the sample
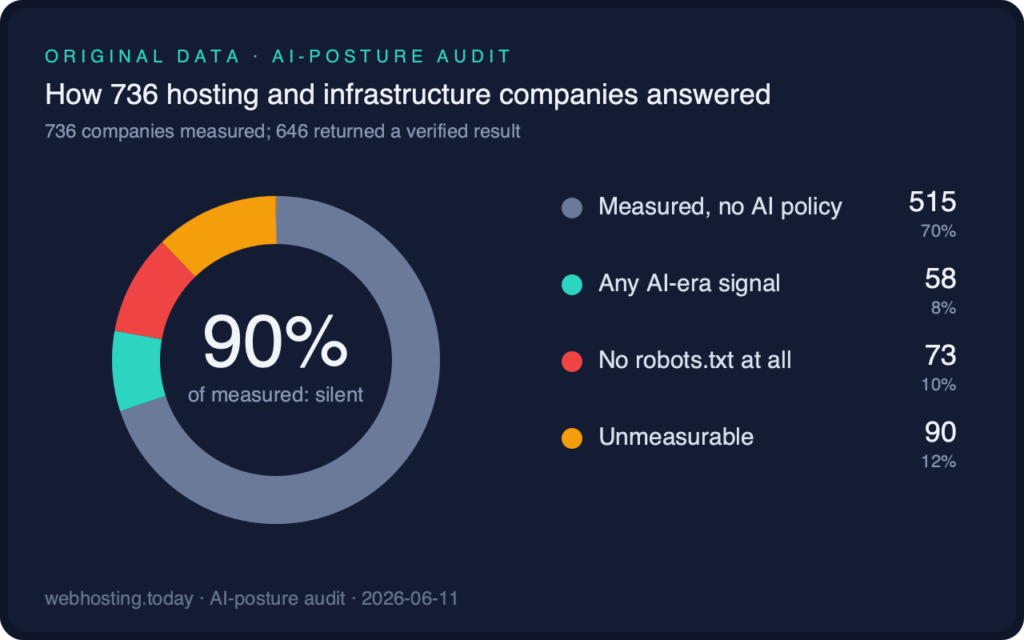
Of 736 audited companies, 90% of those measurable expressed no AI-crawler policy of any kind. Measurement: webhosting.today, June 11, 2026.
The Numbers
| Posture | Count | Companies |
|---|---|---|
| Names AI crawlers in robots.txt | 47 / 573 | Cloudflare, Akamai, Oracle, Tencent Cloud, Liquid Web, Render, A2, hosting.com, Squarespace, Vultr, Dynadot, eukhost, FastComet, TMDHosting, MochaHost, Webcentral, UK2, mijn.host, Verpex, Donweb, Fasthosts, phoenixNAP, GlowHost, lolipop.jp, WPMU DEV, WordPress VIP, reg.ru, claranet.com, middlehost.com, and 18 more from the expanded passes, all named in the appendix |
| Declares Content-Signal | 25 / 573 | ai-train=yes: Cloudflare, Liquid Web, Hover, Kinsta · ai-train=no: Render, Vercel, InterServer, pair, eukhost, mijn.host, plus the fifteen-brand Cloudflare-managed cohort |
| References llms.txt | 8 / 573 | Cloudflare (plus llms-full.txt), Oracle, GoDaddy, eukhost, Raiola Networks, WebSupport.sk, Louhi, MiddleHost; the .ph registry references its own, and Thailand’s THNIC publishes one unreferenced |
| Publishes /llms.txt (census, separate dimension) | 110 / 589 | 60 curated · 28 plugin-generated · 13 linkless · 9 oversized; among them Hostinger, SiteGround, DreamHost, Contabo, Shopify, Wix, WordPress.com, Azure, fly.io; full classified list in the appendix |
| Any AI-era signal at all | 58 / 573 (10%) | the above, deduplicated |
| No AI-specific configuration | 515 / 573 (90%) | including every mass-market hosting giant, all three hyperscaler marketing domains, Shopify, Wix, WordPress.com, Equinix, Verisign, cPanel, Plesk, and the overwhelming majority of national market leaders around the world |
| Unmeasurable | 90 / 736 | 28 hard HTTP 403s (Cloudways, four Newfold microbrands, Crazy Domains, ConoHa, Vodien and more), 27 challenge pages served with a 200 status (Cafe24, PlanetHoster, Pressable, z.com…), 31 unreachable after repeated attempts on both protocols, 3 other failures, 1 inconsistent responder; six domains initially blocked to one method were verified via a second and counted as measured |
| No robots.txt served (HTTP 404) | 73 / 736 | Hetzner, Afrihost, Simply.com, Hurricane Electric, alwaysdata, Netlify, fly.io, WHMCS, four domain registries, and 61 more, all named in the appendix |
Why the denominators differ. Three bases, three populations, all drawn from the same 736-company sample:
- /736 is the full sample, the base for what is unmeasurable (90) or serves no robots.txt at all (73).
- /573 is the companies whose robots.txt we could read and verify, the base for every robots-policy row.
- /589 is the companies that gave a definitive answer to a separate
/llms.txtfetch. That is a different endpoint from robots.txt, so a slightly different set of domains responds, which is why this one row is counted on its own base.
The bases reconcile exactly: 58 configured plus 515 silent equals the 573 readable; and 573 readable plus 73 with no robots.txt plus 90 unmeasurable equals the full 736.
How We Measured This
The audit is built to be repeated and checked, so the method matters as much as the numbers. We checked each domain for roughly twenty known AI user-agents, Content-Signal lines, and llms.txt/RSL references. Here is exactly how the data was gathered, verified, and graded.
Retrieval
- We retrieved the robots.txt of 736 domains on June 11, 2026.
- Collection ran in eight passes: three list batches, low-parallelism retries, and a post-curation remeasurement of corrected domains with HTTP fallback.
- Every domain was attempted with two independent automated retrieval methods.
Verification and exclusions
- Every counted file had to return HTTP 200 with robots-plausible content: the first directive line a comment, User-agent, Sitemap, or Content-Signal.
- 403-blocked domains were re-attempted with the second method and counted only on success.
- Twenty-one domains served HTML challenge pages with a 200 status; a content-plausibility check caught and excluded them. One, SiteGround, was recovered via the second method.
- One domain returned inconsistent responses across runs and was excluded entirely.
- HTML 404s were classified as serving no robots.txt.
- Empty 200-status files were counted as valid allow-all robots.txt.
- The plausibility check accepts BOM-prefixed files and Yandex-style Host:/Clean-param directives.
- 31 domains failed from our measurement network across repeated attempts on both protocols; we report them as unreachable rather than guessed at.
- Defunct domains, duplicate aliases, and non-industry entries were excluded, and entries were normalized to operators’ primary domains before grading.
The historical baseline
- For the time comparison we used the Internet Archive Wayback Machine, taking the nearest snapshot to June 11, 2025, one year before the audit.
- Snapshots were retrieved via the availability API and raw-content endpoint for the 35 companies configured in the first 250-company pass plus 25 giants.
- Domains without a usable 2025 snapshot are reported as such, not interpolated.
The llms.txt census
- Separately from robots.txt, we fetched /llms.txt for every sample domain.
- We classified the 110 hits by spec-format heading, link presence, size, and SEO-plugin generator fingerprints.
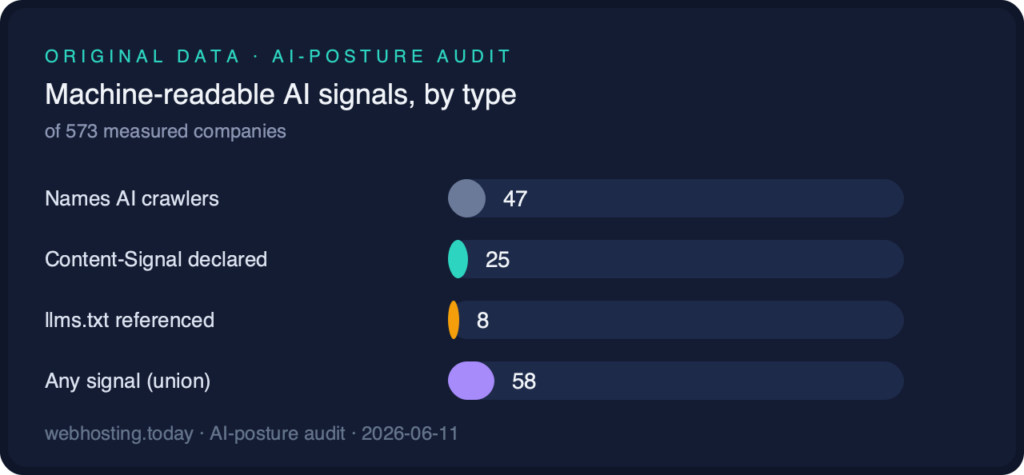
Named crawler rules remain the most common signal; llms.txt the rarest.
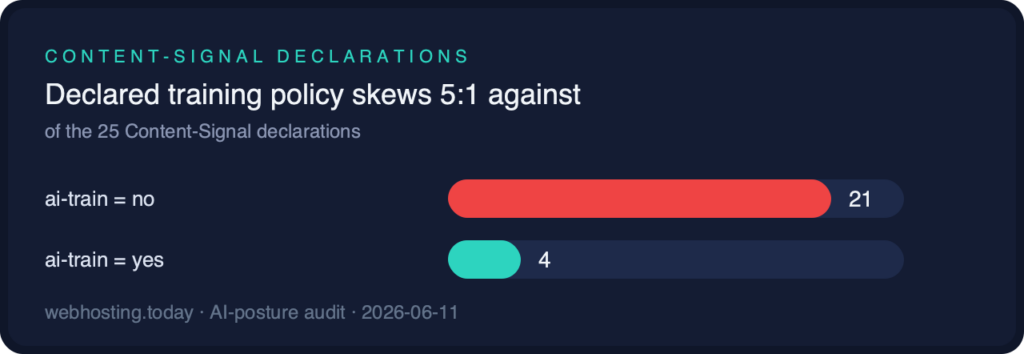
Where companies declare a training policy at all, refusal dominates.
Who Gets Named: The Crawler League Table

Mentions across the 48 files that name any AI crawler. Naming is not welcoming: a mention can be an Allow or a ban.
Forty-eight files in the sample name at least one AI crawler, and the roll call has a clear hierarchy. The order of mentions across those 48 files:
- GPTBot (OpenAI): 39 mentions, 81% of naming files. Whatever a company decides about AI, OpenAI’s trainer is the bot it decides about first.
- Google-Extended: 32
- CCBot (Common Crawl): 29
- ClaudeBot (Anthropic): 28
- Applebot-Extended: 24
- meta-externalagent (Meta): 23
- Bytespider (ByteDance) and Amazonbot: 21 each
- ChatGPT-User: 15
- PerplexityBot: 14
One name stands out for the opposite reason. Bytespider, ByteDance’s crawler, appears in 21 files, and in every file we inspected that treats it individually, the treatment is exclusion. Liquid Web admits every major AI crawler and bans Bytespider alone. The fifteen-brand Cloudflare cohort bans it as standard. Files that merely list it among others never single it out for welcome.
The industry’s revealed trust ranking is unambiguous: OpenAI and Anthropic get doors, sometimes with conditions; TikTok’s parent gets locks. We could find no second crawler with that distinction.
The Segment Scorecard: No Layer of the Stack Leads
| Segment | Configured | Detail |
|---|---|---|
| CDNs | 2 / 5 | Cloudflare (A), Akamai (B); Fastly, Bunny, and Gcore: silent, despite Fastly co-backing the RSL licensing standard |
| Hyperscale clouds | 2 / 6 | Oracle (A), Tencent (B); AWS, Azure, Google Cloud, Alibaba: silent in robots, though Azure publishes a 47KB llms.txt |
| Developer PaaS | 2 / 7 | Render (A), Vercel (B); Railway, Heroku, UpCloud silent; Netlify and fly.io serve no robots.txt at all |
| Managed WordPress | 2 / 10 | Kinsta and WordPress VIP (both B); WP Engine, Pagely, Rocket, Flywheel, Raidboxes, Mittwald, Servebolt silent; Pressable unmeasurable |
| Mass-market top 20 | 2 / 20 | GoDaddy (B, llms.txt only) and Squarespace (B, undifferentiated list); the other eighteen, from Bluehost to Wix, have nothing |
The uniformity is the finding. Configuration rates do not rise with technical sophistication: the developer platforms score the same two-per-segment as the discount shared hosts, and the managed WordPress tier, the segment whose customers are most exposed to AI crawl load, scores 2 of 10 with its two largest players silent or unmeasurable. Whatever drives the configured minority, it is not segment culture; it is individual decisions, and most often, as the cohort shows, a CDN making the decision for you.
The Five Strategies of the Configured Fifty-Eight
The fifty-eight configured companies did not converge on one answer. They split into five recognizable strategies, each internally coherent and each tied to what the company actually sells. Read together, they are a menu.
Strategy 1: The open door, flung wide
Cloudflare, Akamai, Oracle, Tencent, Dynadot.
The two CDNs that operate the web’s crawl-control infrastructure both explicitly welcome the crawlers:
- Cloudflare names eight crawlers and allows them all, atop an ai-train=yes Content-Signal and the sample’s only llms-full.txt.
- Akamai names some twenty-five, down to DeepSeek-Crawler and ERNIE-Bot, and grants every one
Allow: /.
This is not hypocrisy but arbitrage. The companies monetizing crawl restriction want their own marketing maximally ingested: their content is advertising, their product is the toll booth. Oracle’s file is the sample’s most articulate, each bot annotated with its function and training implications (“Opt-out here if I don’t want content in GPT-4o or GPT-5”), the only trillion-dollar cloud whose robots.txt reads like someone senior approved it.
Strategy 2: The selective refusal
Liquid Web, Render, Vercel, InterServer.
- Liquid Web runs the most sophisticated file in hosting proper: ai-train=yes Content-Signal, every major AI crawler individually allowed, and Bytespider alone blocked outright, a considered judgment about which AI company forfeited trust.
- Render inverts it: every bot named and admitted, but a Content-Signal declaring ai-train=no, ai-input=no. You may visit, you may not learn. Access and license are unbundled, precisely the distinction the RSL standard formalizes.
- Vercel and InterServer split the same way (train no, input yes), each coherent with its business: a PaaS protecting its documentation as a business asset, a host protecting two decades of community reputation while welcoming the citations it runs on.
Strategy 3: The catalog play
GoDaddy, and only GoDaddy.
A curated llms.txt pointing agents at markdown documentation of pricing, domains, payments, and its Airo AI builder. GoDaddy skipped the question everyone else is fumbling (“who may crawl?”) and answered the commercial one (“what should the machines read?”).
Strategy 4: The outsourced conscience
Fifteen brands and counting: Hosting.com, FastComet, TMDHosting, Webcentral, UK2, MochaHost, Doteasy, HostingRaja, ColombiaHosting, id.ie, Kebir Host, mi.com.co, Nasani, Libya’s Libyan Spider, and Germany’s NetHit.
These brands span all six inhabited continents and multiple ownership groups, yet they carry the same Cloudflare-managed robots.txt (eight of them byte-identical at 1,737 bytes). That file:
- Opens with a legal preamble reserving rights under Article 4 of EU Directive 2019/790, the text-and-data-mining opt-out.
- Declares search=yes/ai-train=no.
- Blocks the training crawlers individually.
- Is labeled, in the file itself, “BEGIN Cloudflare Managed content.” None of them wrote it.
Their CDN shipped the policy as a managed feature. This is the audit’s most predictive finding, because it shows how the silent 89% will eventually get configured: not by strategic decision but by infrastructure default. It is exactly the managed-service dynamic this publication has argued hosts should be selling to their customers, observed here happening to the hosts. The toll-booth layer is configuring the industry that was supposed to configure the web.
Strategy 5: Enumeration without policy, and one overachiever
mijn.host, Squarespace, Vultr.
The counterpoint to the silent giants is mijn.host, a Dutch independent whose robots.txt is the most granular file in the entire 736-company sample: twenty-four per-bot Content-Signal declarations, each citing the IETF draft (draft-romm-aipref) by name. A boutique host outconfigures AWS, Google Cloud, and every mass-market brand on earth.
Others are stuck mid-deliberation:
- Squarespace names a dozen AI crawlers and then routes them into the same path rules as every other agent: bots acknowledged, nothing decided.
- Vultr restricts GPTBot from its docs and says nothing else.
Even that is at least a stage past the IONOS file still addressing Yahoo’s Slurp, or HostGator’s, still warning off the crawler of Digg, a site that shut down in 2012.
The Grades, and the Clock Behind Them
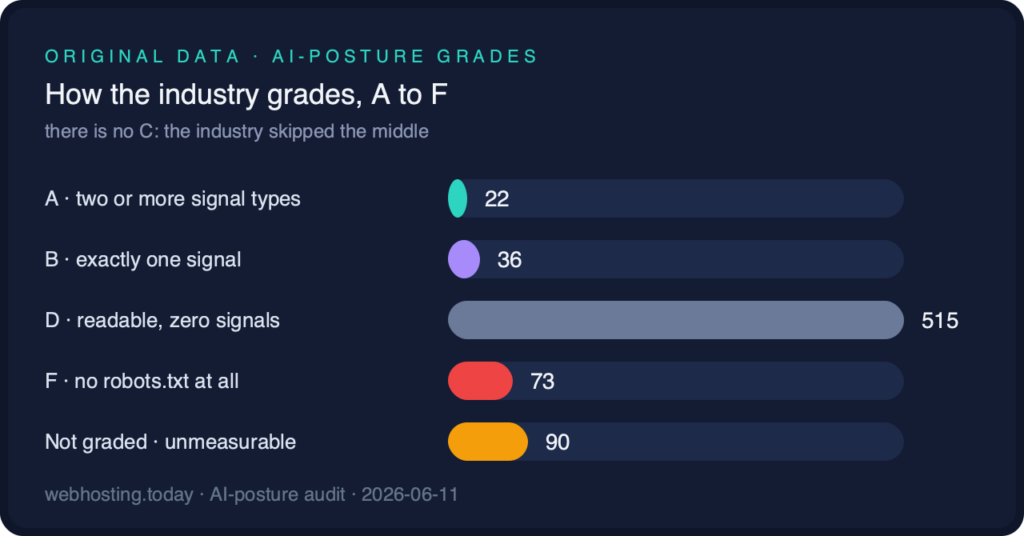
The grade distribution. There is no C because the rubric has no middle: companies either declared something or declared nothing.
The grading rubric
To make the audit comparable across editions, we grade it. The rubric is mechanical and reproducible from the published data:
- A requires two or more signal types (named crawler rules, a Content-Signal, an llms.txt).
- B is exactly one signal type.
- D is a readable robots.txt with no AI signal of any kind.
- F is no robots.txt at all.
- Unmeasurable domains are not graded.
There is no C, because the rubric has no middle: a company either declared something or it declared nothing. The distribution: 22 A, 36 B, 515 D, 73 F, with 90 unmeasurable left ungraded.
Inside the A tier: who actually wrote the best scores
Two facts inside the A tier deserve their own sentence.
- Two in three of the best scores were written by a CDN, not by the companies wearing them. Fifteen of the twenty-two A grades belong to the Cloudflare-managed cohort: eight byte-identical files plus localized variants, spanning all six inhabited continents from Canada and Colombia to India, Vietnam, Australia, Libya, and Germany.
- The hand-written A grades number seven: Cloudflare, Oracle, Liquid Web, Render, eukhost, mijn.host, and the audit’s smallest member of the tier, MiddleHost, which pairs five named crawlers with a robots-referenced llms.txt.
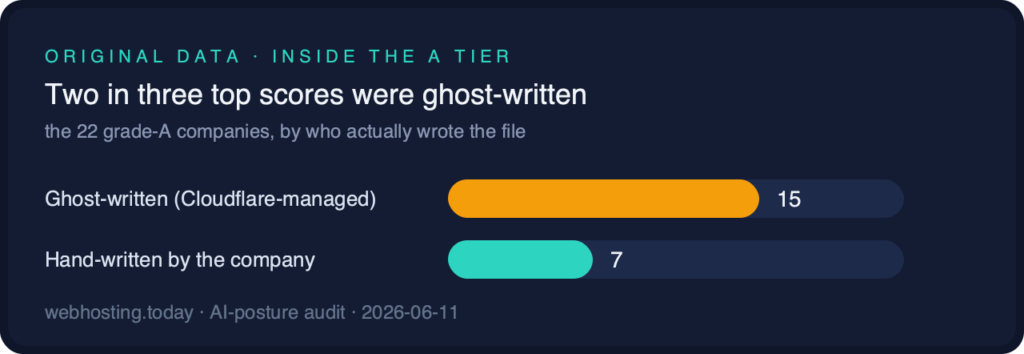
The 22 grade-A companies by authorship. Fifteen of them wear a file their CDN wrote; only seven are hand-written.
Configured companies surface in every geography once domains are read at the operator level: Claranet names crawlers, Libya’s Libyan Spider anchors the cohort’s African corner, Malaysia’s ServerFreak names Google-Extended, and Finland’s Louhi is the seventh robots-referenced llms.txt. The full roster appendix below names every grade, and the next edition will publish movements.
The clock behind the grades: what the Wayback Machine showed
The grades gain their force from the clock, so we measured that too. Using the Internet Archive’s Wayback Machine, we retrieved the robots.txt of the 35 companies configured in our first 250-company pass and 25 industry giants as they stood around June 11, 2025, one year before this audit. The findings reframe the whole picture. Of the 35 companies configured in that first pass:
- Only seven verifiably had any AI signal a year ago: hosting.com, FastComet, Fasthosts, Vultr, Dynadot, WPMU DEV, and InterServer (whose nearest snapshot is August 2025).
- Fifteen had silent files in their mid-2025 snapshots, including Cloudflare itself, Oracle, Render, the managed cohort’s members, and mijn.host. The policies this article praises are mostly less than twelve months old.
- Thirteen had no usable 2025 snapshot, which we report rather than guess about.
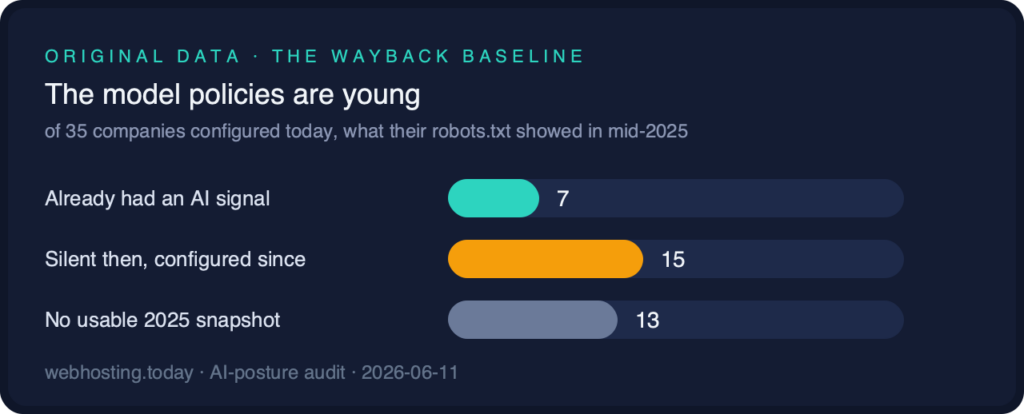
The corollary cuts both ways: the model policies are young, so catching up is demonstrably a months-not-years project, and nobody silent today can plead that the leaders had a decade’s head start.
Two structural dates that sharpen the timeline
- September 24, 2025: the Content Signals standard launched. Cloudflare published the policy and began adding it to every robots.txt file it manages. All twenty-five Content-Signal declarations in this audit are by definition under nine months old, and the fifteen-brand managed cohort acquired its Article 4 rights reservations through exactly that mechanism.
- The giants’ silence now has a verified duration. Eleven major brands had no AI signals in June 2025 and have none today: Bluehost, OVHcloud, DreamHost, WordPress.com, Contabo, Netcup, DigitalOcean, Linode, Equinix, and the AWS and Google Cloud marketing domains. Their robots.txt files have sat through the entire first year of the agentic web, the year of AI Crawl Control launches, agent-readiness keynotes, and pay-per-crawl betas, without a single line changing.
Two trajectories moved during the year. InterServer’s August 2025 file blocked training crawlers by name; today the names are gone, replaced by a single ai-train=no Content-Signal, a tidier expression of the same refusal. FastComet is the inverse case: it had hand-written OpenAI and Perplexity stanzas in June 2025, which its CDN’s managed block has since absorbed and standardized.
The llms.txt Census: The Second Wave Nobody Signposted
Of 35 companies configured today, only seven were configured a year ago. The model policies are mostly under twelve months old.
The census measures publication at the standard /llms.txt path, independent of whether robots.txt mentions it. Only 8 of the 110 publishers signpost the file from robots.txt.
Two different questions, two different instincts
Declared crawl policy is one dimension; published content for machines is another, and it deserves its own definition. The grades above score what a company declares in robots.txt. The census in this section measures something separate: whether the company publishes a file at the standard /llms.txt path, regardless of whether anything points to it.
The two waves are different ages and different instincts:
- Robots policy answers “who may take my content.”
- The catalog answers “what should machines know about my products.”
And the industry is measurably more comfortable with the second question.
The adoption gap: publishing beats signposting fourteen to one
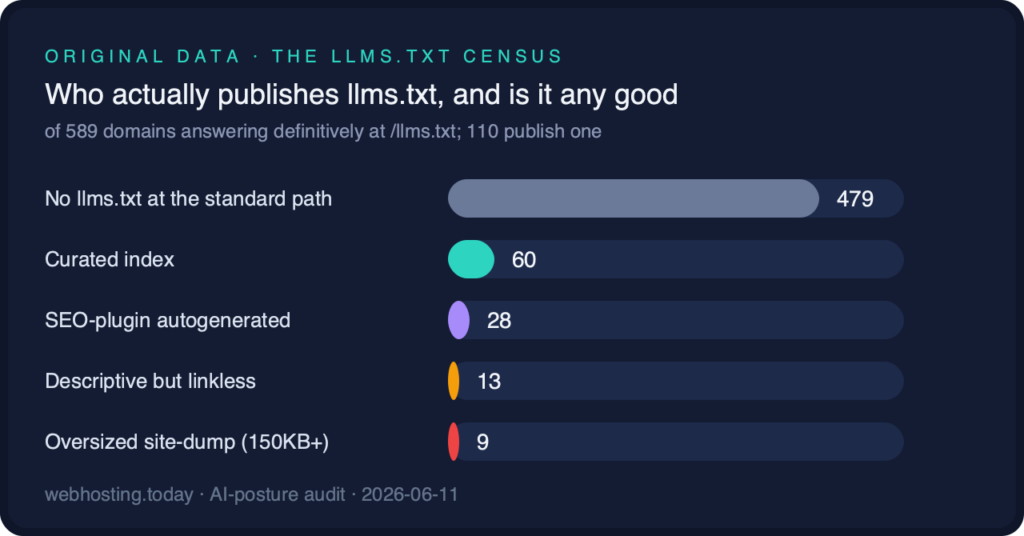
We fetched /llms.txt for all sample domains; 589 answered definitively (the TLS-unreachable and hard-blocked set largely overlaps the robots audit). The result upends the robots-only picture:
- 110 companies publish an llms.txt, fourteen times the eight that reference one from robots.txt.
- 102 of those 110 adopters never added the one-line signpost. The llms.txt convention has no discovery mechanism beyond the path itself, so the file exists but nothing points to it.
- Many publishers are robots-graded D, including Hostinger, SiteGround, DreamHost, Contabo, Shopify, Wix, WordPress.com, and Microsoft’s Azure marketing domain.
- fly.io serves an llms.txt while serving no robots.txt at all.
Is what they publish any good? Just over half
We classified all 110 files by mechanical criteria (spec-format heading, presence of links, file size, generator fingerprints). They split four ways:
- 60 are curated indexes in the spirit of the specification: a title, a description, sectioned links to real documentation. Shopify’s 861-byte file is the genre’s minimalist model; GoDaddy’s points machines at markdown documentation of its pricing.
- 28 are SEO-plugin output. Yoast, Rank Math, and All in One SEO now autogenerate llms.txt files, which means a quarter of the industry’s adoption happened as a plugin default rather than a decision: the same outsourced-conscience mechanism that wrote fifteen robots policies via Cloudflare, operating one layer up the stack.
- 13 are descriptive but linkless, paragraphs about the company with nothing for an agent to follow. Kinsta, Porkbun, and InterServer sit in this group.
- 9 are oversized site-dumps of 150KB or more, against a specification whose entire point is a concise index: e-monsite’s runs to 331KB, Webempresa’s to 727KB, Ultahost’s to 431KB, Selectel’s to 512KB, and Hostinger’s 292KB file is impeccably structured and, at that size, hostile to the context windows it is meant to serve.
One anomaly completes the census: Oracle’s robots.txt references an llms.txt that returns 404, a signpost to a missing file, on the domain whose crawler annotations we praised above. Machine-readability, it turns out, also needs link checking. And among the Big Three clouds, only Microsoft answers the catalog question, with a 47KB Azure llms.txt against nothing at AWS and Google Cloud.
110 files nobody is guarding
The census doubles as a warning. The 110 files that AI agents will ingest verbatim are 110 new prompt-injection surfaces that, as far as we can observe, nobody sanitizes, signs, or monitors for tampering. The supply-chain variant is the one to lose sleep over: 28 of these files are autogenerated by three SEO plugins, so a single compromised plugin update would inject content into dozens of agent-facing catalogs simultaneously, on trusted hosting-industry domains, in a channel no scanner currently watches. We will return to this attack surface in a separate analysis; the census above is its baseline measurement.
What the Silent Majority’s Silence Means
As in any null result, there are two honest readings.
The generous reading: enforcement lives elsewhere
robots.txt is not where enforcement lives. WP Engine demonstrably blocks AI crawlers at the network layer while its robots.txt says nothing, and GoDaddy’s customer-facing crawl controls operate through Cloudflare’s edge. Active policy can hide behind a silent text file.
But the file is where declared, machine-readable policy lives, the layer that the CMA’s unbundling order, the EU’s content-use investigations, and the RSL licensing economy all reference. On that layer, 90% of the 573 measured companies have written nothing: every hyperscaler marketing domain, every mass-market hosting giant, and the overwhelming majority of national market leaders from Brazil to Japan.
The less generous reading: the artifacts give it away
The files themselves argue against the strategy excuse. Files naming msnbot and duggmirror are not edge-versus-text strategy splits; they are files no one strategic has opened in a decade, sitting on the front doors of companies whose 2026 marketing leads with the agentic web.
- The industry is barely better than the web it hosts. Cloudflare’s own scan found 4% of top domains declaring AI preferences; the infrastructure industry, at 11% counting generously, is only marginally ahead, and dramatically worse than its own sales decks.
- The platform layer is among the silent. The seventy-three companies serving no robots.txt at all include Hetzner, Afrihost, Hurricane Electric, and two developer-platform darlings, Netlify and fly.io. The layer that hosts the modern web publishes no machine-readable policy file whatsoever.
Notes from the Margins of the Dataset
How to read a policy’s authorship from the file itself
The dataset yields a forensic method. Cloudflare-managed policies are recognizable by three fingerprints:
- The literal marker
BEGIN Cloudflare Managed content. - A length of exactly 1,737 bytes in the unlocalized version.
- A Content-Signal written without spaces (
search=yes,ai-train=no).
Hand-written declarations, by contrast, space their values (search=yes, ai-input=yes, ai-train=no at eukhost, Vercel, mijn.host). Anyone can apply this to their own provider in ten seconds, which is the point: in a market where policy is increasingly ghost-written by infrastructure, provenance is legible in the bytes.
Fifty companies serve a literally empty robots.txt
Not a missing file, an empty one: a 200 response with zero bytes of directives, from names including StableHost, HostArmada, Sprinthost, and SiteHost New Zealand. An empty file is valid and means allow everything, but as a statement of posture it is its own category: the company that created the file and then said nothing at all. They are counted with the wildcard-only majority and grade D, but they mark the exact spot where a one-line Content-Signal would cost the least.
The registry layer, measured properly: 33 registries, one configured
We audited the naming layer as its own cohort: the registries of .de, .uk, .eu, .fr, .it, .be, .nl, .ch, .se, .no, .dk, .pl, .cz, .jp, .tw, .cn, .au, .br, .ar, .in, .th, .by, .ua, .lv, .ae, .cl, .is, .il, .hk, .ph, plus .org’s Public Interest Registry, Identity Digital, and Verisign, operator of .com itself. The result is starker than the hosting industry’s:
- 26 of the 27 measurable registries grade D.
- Four serve no robots.txt at all: DENIC, auDA, TWNIC, and Poland’s NASK. The institutions that operate the internet’s naming system include four that skip the web’s oldest machine-readable convention entirely.
- The only configured registries on earth are in Southeast Asia. The Philippines’ dot.ph references an llms.txt from robots.txt (grade B, the layer’s sole non-D grade), and Thailand’s THNIC publishes a hand-curated llms.txt of its own.
The institutions that will eventually be asked to anchor agent identity, as the DNS-based agent registries this publication has covered propose, currently have less declared AI posture than a mid-size Dutch host.
The Netherlands leads, and Automattic is its own control group
The Netherlands is the sample’s most agent-literate market. Three Dutch providers sit in the configured minority (mijn.host with the sample’s most granular file, Cyso, EasyHosting.nl), a density no other national market matches.
Automattic, meanwhile, demonstrates that posture is not even consistent within a single firm:
- WordPress.com is silent in robots but publishes an llms.txt.
- Its enterprise arm WordPress VIP names exactly one obscure crawler (Timpibot).
- Its agency platform Pressable serves challenge pages to measurement.
One company, four postures, no policy.
The discovery problem has a standards-track answer almost nobody implements
GoDaddy invented its own discovery mechanism by listing llms.txt as a Sitemap entry, a creative abuse of an unrelated directive. The actual standards-track answer exists: the IETF’s AI Preferences draft (draft-romm-aipref), which formalizes machine-readable AI-use declarations. In our 736-company sample, exactly one company cites it: mijn.host, a Dutch boutique. The gap between standard and adoption is the whole audit in miniature.
Policy churn has already started
The Wayback comparison shows not just young policies but second drafts: InterServer’s August 2025 file banned training crawlers by name and has since been rewritten as a single ai-train=no Content-Signal; FastComet’s hand-written OpenAI stanzas were absorbed into its CDN’s managed block. The next editions of this audit will be measuring rewrites, not just adoption.
Blocked to our agents means blocked to everyone’s agents
Twenty-eight companies, Cloudways among them, refuse automated retrieval outright. Whatever the security rationale, the commercial effect in the agentic channel is identical to the one the Renewal Multiplier Index documented for hidden prices: what a measurement agent cannot read, a customer’s shopping agent cannot read either. A robots.txt no robot may fetch is its own kind of statement.
Robots.txt spans three orders of magnitude
The smallest measured files are 14 bytes (Mythic Beasts, premium.pl); the largest is Dynadot’s at 30 kilobytes. Neither extreme correlates with AI posture: Dynadot’s 30KB names one AI agent; Tucows runs on 40 bytes of nothing. Effort and intentionality are different axes.
What to Do Now
1. Pick one of the five strategies on purpose
The configured fifty-eight have done the design work for you. Match the choice to what your content actually is:
- Welcome maximally if your content is marketing (the CDN position).
- Unbundle access from license if your content is product (Render’s train-no, visit-yes).
- Differentiate by crawler if you have trust judgments to express (Liquid Web’s Bytespider exception).
- Publish the catalog if agents shopping your prices serves you, and per today’s Index it serves almost everyone (the GoDaddy position).
- Accept your infrastructure’s managed default, but knowingly rather than by omission.
2. Align the file with the stack you already sell
A host marketing AI crawl control to customers while its own domain expresses no policy is running the 2009 routine of selling SSL from a site without it. The fix is an afternoon:
- A Content-Signal line.
- Named stanzas matching what the edge enforces.
- An llms.txt with the pricing and docs in markdown.
The citation economics this publication has documented all year, and the agent-shopping asymmetry the Index quantified today, make machine legibility an acquisition channel, not housekeeping.
3. Then sell the audit to the customer base
Seven hundred thirty-six companies scored 58-for-573 on AI-posture basics; their customers, on the general web’s 4% baseline, score worse. Every row of this table is a managed-service SKU:
- AI-visibility audit.
- llms.txt-as-a-service.
- Crawl-policy management.
- Article 4 rights-reservation templates.
Layer that moves first (the CDN) captures the configuration by default. Hosts can be the ones shipping that default to their fleets, or the ones receiving it from above. The audit suggests which way it is currently going.
Twelve Conclusions
- Declared AI policy is the exception, at one in ten. 90% of 573 measurable companies express nothing: no crawler rules, no Content-Signal, no catalog reference.
- The best postures are mostly ghost-written. Fifteen of twenty-two A grades sit on one CDN’s managed file; a quarter of llms.txt adoption is SEO-plugin output. Infrastructure defaults, not decisions, are configuring the industry.
- Where companies do decide, they refuse training and welcome citation. Content-Signals skew 5:1 ai-train=no while search and ai-input stay open: the industry’s revealed preference is be quoted, not learned from.
- GPTBot is the reference point; Bytespider is the pariah. OpenAI’s trainer appears in 81% of naming files; ByteDance’s is the only crawler named principally to be banned.
- No segment leads. CDNs, clouds, PaaS, managed WordPress, and mass-market hosts all configure at roughly two per segment. Sophistication does not predict posture.
- The publishing instinct beats the policy instinct fourteen to one. 110 companies answer “what should machines know about us” against eight that signpost it, on a path with no standard discovery mechanism.
- Half the catalogs are good; the other half are noise. 60 curated indexes against 28 plugin dumps, 13 linkless stubs, and 9 token-hostile site-dumps up to 727KB.
- Everything is younger than it looks. Only 7 of the first-pass 35 configured companies had any signal in mid-2025; Cloudflare’s own model policy, and every Content-Signal in existence, postdates September 2025. Catching up is a months-not-years project.
- The giants’ silence is verified, not assumed. Eleven major brands, AWS and Google Cloud included, are Wayback-confirmed unchanged across the entire first year of the agentic web.
- The naming layer is no better than the hosting layer. 26 of 27 measurable registries grade D, four serve no robots.txt, and the only registries on earth with any AI signal are .ph (graded B) and .th (an unreferenced llms.txt).
- Unreadability is a posture too. 28 companies block measurement outright and 73 serve no robots.txt; in the agentic channel both read identically to a customer’s shopping agent: nothing there.
- The whole surface is unguarded. 110 agent-facing catalogs that nobody signs or sanitizes, 28 of them writable by compromising one of three SEO plugins, constitute a supply-chain attack surface that has a baseline measurement now and a security model not yet.
The Audit Is Repeatable. That Is the Point.
This measurement took one afternoon and public files; every AI agent that shops, cites, or licenses content can and will repeat it continuously. We will re-run it quarterly alongside the Renewal Multiplier Index and report movement against this baseline. Edition one’s summary: the industry that sells the machine-readable web is 11% machine-readable about its own intentions, the most deliberate policies in the sample belong to the toll-booth operators, one unexpected cloud, and one small Dutch host with an IETF draft citation, and the most common AI policy among the giants of mass-market hosting is a file last strategically edited when Digg still existed. Silence was a defensible default in 2023. In the year the buyers became agents and the regulators began demanding declared policy, it is a position, just one that 515 of the industry’s measured companies appear to be holding by accident. The next edition will show who noticed.
Appendix: The Full Audited Roster
Grade A (22), two or more signal types: hosting.com‡, cloudflare.com‡, colombiahosting.com, doteasy.com, eukhost.com°, fastcomet.com†, hostingraja.in, id.ie, kebirhost.net, libyanspider.com, liquidweb.com°, mi.com.co, middlehost.com, mijn.host‡, mochahost.com‡, nasani.vn, nethit.de, oracle.com‡, render.com‡, tmdhosting.com°, uk2.net‡, webcentral.com.au°.
Grade B (36), exactly one signal type: akamai.com°, alastyr.com, claranet.com, cyso.com, donweb.com‡, dot.ph, dynadot.com†, easyhosting.nl, fasthosts.co.uk†, fastvps.ru, glowhost.com°, godaddy.com°, hitme.pl, hosting.cl, hosting.com†, hover.com‡, interserver.net†, intl.cloud.tencent.com°, kinsta.com‡, lolipop.jp‡, louhi.fi, namespro.ca, pair.com‡, phoenixnap.com°, power-netz.de, quickhost.nl, raiolanetworks.com°, reg.ru‡, squarespace.com°, vercel.com°, verpex.com‡, vultr.com†, web-hosting.net.my, websupport.sk‡, wpmudev.com†, wpvip.com°.
† = AI signals already present in the mid-2025 Wayback snapshot ‡ = mid-2025 snapshot had none (policy younger than 12 months) ° = no usable 2025 snapshot no marker = outside the 2025 baseline set.
Grade D (515), readable robots.txt, zero AI signals: 1-grid.com, 10web.io, 123-reg.co.uk, 1984.is, 1blu.de, 1gb.ru, 20i.com, 34sp.com, abion.com, accuwebhosting.com, acens.com, active24.cz, activecloud.by, adminvps.ru, aeserver.com, afeeshost.com, afnic.fr, aftermarket.com, ahost.uz, alfahosting.de, alibabacloud.com, all-inkl.com, amen.fr, ans.co.uk, antagonist.nl, anymhost.id, aplus.net, area.lv, arsys.es, aruba.it, ascio.com, atw.hu, awardspace.com, aws.amazon.com, axarnet.es, az.pl, azdigi.com, azehosting.net, azure.microsoft.com, bahnhof.se, banahosting.com, bandzoogle.com, bb-online.com, beget.com, bhosted.nl, bigcommerce.com, bigrock.in, binarylane.com.au, bit.nl, blacknight.com, bluehost.com, bluehosting.cl, bravenet.com, brixly.com, bunny.net, canspace.ca, cdmon.com, centralnicreseller.com, cenuta.com, cheaperdomains.com.au, chemicloud.com, cityhost.ua, clausweb.ro, cleura.com, cloud.google.com, cloud86.nl, cloudsigma.com, cnnic.cn, combell.com, conetix.com, contabo.com, convesio.com, cosmotown.com, cpanel.net, cpi.ad.jp, cscdbs.com, curanet.dk, cyberfolks.hr, cyberfolks.pl, cyon.ch, dandomain.dk, datacom.mn, ddos-guard.net, dewaweb.com, df.eu, dhosting.pl, digitalocean.com, digitalpacific.com.au, digitalrealty.com, dima.hu, dmsolutions.de, dnsbelgium.be, dogado.de, domain.by, domainesia.com, domainhotelli.fi, domainit.com, domainmaster.cz, domainpeople.com, domaintechnik.at, domainthenet.com, domdom.hu, domena.pl, domenai.lt, domenca.com, domene.no, domeneshop.no, domeny.tv, dominiok.it, dondominio.com, doruk.net.tr, dothome.co.kr, dotroll.com, dreamhost.com, dreamithost.com.au, dreamwebhosting.net, e-monsite.com, easy.gr, easyhost.be, easyname.com, easyspace.com, edis.global, egensajt.se, ehost.pl, elin.hu, encirca.com, endora.cz, entorno.com, eolas.fr, epag.de, equinix.com, estugo.de, eurid.eu, eurobyte.ru, exabytes.com, exohosting.cz, exonet.nl, exonhost.com, exoscale.com, fastly.com, fastmail.com, firestorm.ch, firstvds.ru, flexwebhosting.nl, fornex.com, freehostia.com, freemium.fr, freeola.com, freethought.uk, funio.com, gabia.com, gandi.net, gazduire.net, gcore.com, getflywheel.com, getspace.us, gigahost.dk, gigaserver.cz, gkg.net, go54.com, goneo.de, gransy.com, green.ch, greengeeks.com, grupoloading.com, guzelhosting.com, handyhost.ru, hawkhost.com, heartinternet.uk, heberjahiz.com, heroku.com, hitrost.com, hivelocity.net, home.pl, hospedando.mx, host.it, hostafrica.co.za, hostalia.com, hostarmada.com, hostcreators.sk, hostdime.com, hosted.nl, hostek.com, hoster.by, hoster.kz, hoster.ru, hosterpk.com, hosteur.com, hosteurope.de, hostfly.by, hostgator.com, hostico.ro, hostido.pl, hostiman.ru, hostinet.com, hosting-mexico.net, hosting.de, hosting.kr, hosting.nl, hosting2go.nl, hostinger.com, hostingpalvelu.fi, hostingplus.cl, hostinguk.net, hostiq.ua, hostiran.net, hostkey.com, hostland.ru, hostmaster.ua, hostnet.de, hostnet.nl, hostopia.com, hostpapa.com, hostpoint.ch, hostpro.ua, hoststar.ch, hosttech.ch, hostup.se, hostwinds.com, ht-systems.ru, http.net, i-host.pl, icasei.com.br, idcloudhost.com, identity.digital, ihc.ru, ihouseweb.com, imena.ua, imweb.me, inet.vn, infomaniak.com, inmotionhosting.com, integrity.hu, interdominios.com, interip.nl, internetstiftelsen.se, internex.at, iomart.com, ionos.com, ip-projects.de, iq.pl, irpower.com, isnic.is, iteasy.co.kr, iwantmyname.com, iwelt.de, jagoanhosting.com, jaguarpc.com, jino.ru, joker.com, jpdirect.jp, jprs.jp, kagoya.jp, kamatera.com, keliweb.com, kinghost.com.br, knownhost.com, krystal.uk, kualo.com, kylos.pl, latincloud.com, latinoamericahosting.com, lcn.com, leaseweb.com, letshost.ie, lexsynergy.net, lh.pl, lima-city.de, linkeo.com, linknow.com, linode.com, locaweb.com.br, loopia.se, lucushost.com, mailplug.com, manitu.de, masterhost.ru, mchost.ru, mddhosting.com, mediacenter.hu, megagroup.ru, metanet.ch, metaregistrar.com, microware.hu, midominio.do, mihanwebhost.com, mijndomein.nl, mijnhostingpartner.nl, mijninternetoplossing.nl, mirohost.net, missgroup.com, misshosting.com, mittwald.de, mixhost.jp, mojohost.com, mono.net, mvmnet.com, mweb.co.za, mydataknox.com, mydevil.net, myhost.nz, myideasoft.com, mythic-beasts.com, name.com, namebay.com, namecheap.com, namegear.co, namehero.com, names.co.uk, nazwa.pl, neodigit.net, neoserv.si, neostrada.nl, netangels.ru, netcup.com, nethely.hu, nethouse.ru, netnerd.com, netowl.jp, netsons.com, networksolutions.com, netzone.ch, nexcess.net, nexloc.ro, nhanhoa.com, nic.ae, nic.ar, nic.ch, nic.cl, nic.cz, nic.it, nic.lv, nicsell.com, nixihost.com, nomeo.be, nominalia.com, nominet.uk, nordicway.dk, norid.no, nuthost.com, o2switch.fr, oderland.com, omnis.com, one.com, onebit.cz, onepage.io, opalstack.com, optimanet.ch, orangehost.com, oray.com, ovhcloud.com, oxilion.nl, pagely.com, paginesi.it, pananames.com, pantheon.io, pavietnam.vn, pchome.com.tw, piensasolutions.com, pir.org, pixelx.de, planeetta.fi, planethoster.com, plesk.com, plus.hr, porkbun.com, premium.pl, progreso.pl, proisp.no, provider.at, ps.kz, ptservidor.pt, punktum.dk, qservers.ng, quic.cloud, rackforest.com, racknerd.com, rackspace.com, radicenter.eu, raidboxes.io, railway.com, razorhost.in, realtime.at, realtimeregister.com, reclaimhosting.com, register.be, register.it, registro.br, registry.in, regway.com, rocket.net, rosehosting.com, ru-tld.ru, rumahweb.com, sakura.ad.jp, savvii.nl, scalahosting.com, scaleway.com, seeweb.it, selectel.ru, selfhost.de, seohost.pl, sered.net, servebolt.com, serverbyt.com, serverhostgroup.com, serverlet.com, serverplan.com, servers.com, shellit.org, shockhosting.com, shockmedia.nl, shopify.com, shoptet.cz, sidn.nl, site.eu, site123.com, siteground.com, sitehost.co.nz, smartape.ru, smarterasp.net, smarthost.pl, space.net, spaceweb.ru, sphostserver.com, sprinthost.ru, ssdnodes.com, stablehost.com, strato.de, strefa.pl, superhosting.bg, supporthost.com, supremeservers.com, svenskadomaner.se, svethostingu.cz, swizzonic.ch, sybell.hu, systonic.fr, tecnocratica.net, tele3.cz, tenten.vn, thehost.ua, thinline.cz, thnic.co.th, tigertech.net, tilaa.com, timeweb.com, timmehosting.de, top.host, towebs.com, transip.nl, triara.com, triple.nl, truehost.cloud, tucows.com, turbify.com, turkticaret.net, ucoz.ru, ukit.com, ultahost.com, umbler.com, unas.eu, unixstorm.org, unlimited.rs, uolhost.com.br, upcloud.com, upress.io, v2networks.cl, valuehost.com.br, variomedia.de, vas-hosting.eu, ventraip.com.au, verisign.com, versio.nl, vhosting.com, vimexx.nl, vip.nl, vps.net, web4africa.com, web4u.cz, webempresa.com, webglobe.sk, webhosting.com.tr, webhosting.dk, webhostingpad.com, webhouse.sk, webhs.pt, webhuset.no, weblium.com, webnames.ca, webreus.nl, website.com, webspace.uz, websupport.hu, wedos.com, whc.ca, whois.com, wix.com, wordpress.com, world4you.com, worldsoft.ch, worldstream.com, wpengine.com, wpx.net, xel.nl, xneelo.co.za, xserver.ne.jp, yoncu.com, yourhosting.nl, zen.co.uk, zenbox.pl, znetlive.com, zomro.ru, zone.eu, zoner.fi.
Grade F (73), no robots.txt served: afrihost.com, alwaysdata.com, artfiles.de, auda.org.au, bigscoots.com, bitpalast.net, blueboard.cz, canaldominios.com, colorfulbox.jp, d-hosting.nl, denic.de, dns.pl, dnsmanager.nl, domaineasy.com, domainorder.com, dominiofaidate.com, easydns.org, euronic.fi, evanzo.com, f1.com.tw, fabulous.com, fly.io, freehosting.com, gidinet.com, greatnet.de, greenhost.nl, he.net, hetzner.com, hexonet.net, hoasted.eu, hostguy.com, hostneverdie.com, hostpresto.com, hostprofis.com, hypernode.com, idcloudhosting.com, ifastnet.com, inleed.net, instra.com, iphost.gr, knipp.de, kreativmedia.ch, level27.eu, matbao.vn, megacp.com, metunic.com.tr, namespace.ge, netlify.com, privatesystems.net, publinord.it, quick.net.au, rapide.net, rgb365.eu, romarg.com, serviceprovider.nl, simply.com, sitesdepot.com, tarhely.com, thundercloud.uk, tierra.net, tiscomhosting.nl, tld.pl, twnic.tw, versanus.eu, wadax.ne.jp, wannafind.dk, webd.pl, webdock.io, webgo.de, webhost1.com, webland.ch, whmcs.com, yourwebhoster.com.
Not graded, blocked to retrieval (28): cloudways.com, conoha.jp, cpanelhost.cl, crazydomains.com, cyberfolks.ro, domain.com, dongee.com, icuk.net, internet.bs, ipage.com, isoc.org.il, lws.fr, milesweb.com, namestar.com, natro.com, neubox.com, panthur.com, rackhost.hu, register.com, site5.com, tasjeel.ae, time4vps.com, turhost.com, uhost.co.kr, veridyen.com, vodien.com, web.com, wiroos.com.
Not graded, challenge pages with 200 status (27): arenhost.id, atthost.pl, bnamed.eu, cafe24.com, dropcatch.com, forpsi.com, ikoula.com, ilait.com, kei.pl, lemarit.de, majordomo.ru, misterdomain.eu, nameisp.com, nearlyfreespeech.net, njalla.do, nttpc.jp, papaki.gr, pressable.com, proximedia.com, r4l.com, rdash.id, ronet.de, safebrands.fr, serveriai.lt, soverin.net, tsohost.com, z.com.
Not graded, unreachable from our measurement network (31): bigwww.com, controldeservidor.com, cpns.host, domainoo.fr, empretienda.net, hkirc.net.hk, hostbasket.com, idwebhost.id, ignum.com, interbusiness.it, internet1.de, introweb.nl, iptwins.com, js-hpbs.jp, limitis.de, magic-online.fr, nindohost.net, parspack.net, r01.ru, rakko.zone, rcp.net.pe, routit.net, scannet2.dk, servidoresph.com, sotoon53.com, tarhelykozpont.hu, technowave.ad.jp, tmd.cloud, tpiol.com, webhostingireland.ie, wtservers.com.
Not graded, other HTTP failures (3): cretaforce.gr, qweb.nl, rcnoc.com. One domain (dinahosting.com) returned inconsistent robots responses across passes and is ungraded; its llms.txt is counted in the census.
llms.txt census, the 110 publishers. Curated (60): 1984.is, abion.com, accuwebhosting.com, adminvps.ru, alastyr.com, azdigi.com, azure.microsoft.com, bhosted.nl, bigrock.in, brixly.com, cdmon.com, cloudflare.com, contabo.com, cyso.com, dewaweb.com, domainesia.com, donweb.com, dot.ph, dreamhost.com, dynadot.com, easydns.org, eukhost.com, fasthosts.co.uk, fly.io, fornex.com, gcore.com, heartinternet.uk, hitme.pl, hostalia.com, hosting.de, icasei.com.br, intl.cloud.tencent.com, knownhost.com, krystal.uk, liquidweb.com, loopia.se, louhi.fi, mailplug.com, megagroup.ru, middlehost.com, optimanet.ch, plus.hr, railway.com, raiolanetworks.com, realtimeregister.com, render.com, servers.com, shopify.com, siteground.com, squarespace.com, thnic.co.th, turkticaret.net, ucoz.ru, uk2.net, ukit.com, web-hosting.net.my, webhuset.no, websupport.sk, wix.com, wordpress.com. Plugin-generated (28): bahnhof.se, bit.nl, cleura.com, convesio.com, cyberfolks.pl, exabytes.com, heroku.com, hivelocity.net, hosting.nl, hostingplus.cl, hosttech.ch, kamatera.com, latincloud.com, libyanspider.com, plesk.com, power-netz.de, ptservidor.pt, raidboxes.io, rosehosting.com, servebolt.com, shellit.org, upcloud.com, v2networks.cl, versio.nl, wedos.com, xneelo.co.za, yourhosting.nl, zoner.fi. Linkless (13): bigcommerce.com, claranet.com, dhosting.pl, dinahosting.com, doruk.net.tr, gigaserver.cz, hostico.ro, hosting.cl, interserver.net, kinsta.com, porkbun.com, scalahosting.com, vhosting.com. Oversized dumps (9): e-monsite.com, hoster.by, hostinger.com, inmotionhosting.com, mijn.host, selectel.ru, ultahost.com, vercel.com, webempresa.com.
Appendix B: Copy-Paste Starting Points
Three robots.txt blocks and an llms.txt skeleton, modeled on the measured leaders. One caveat applies to all of them: robots.txt and Content-Signals are declarations, not enforcement. Pair them with edge controls if you need the policy to hold against crawlers that ignore polite requests.
1. The open door (the Cloudflare and Akamai position: site content is marketing; you want maximum ingestion and citation):
Content-Signal: search=yes, ai-input=yes, ai-train=yes
User-agent: GPTBot
User-agent: ClaudeBot
User-agent: Google-Extended
User-agent: PerplexityBot
User-agent: CCBot
Allow: /2. The selective refusal (the Render and InterServer position: citation welcome, training declined):
# Rights reserved under Article 4, Directive (EU) 2019/790
Content-Signal: search=yes, ai-input=yes, ai-train=no
User-agent: GPTBot
User-agent: ClaudeBot
User-agent: Google-Extended
User-agent: CCBot
User-agent: Bytespider
Disallow: /3. The differentiated policy (the Liquid Web position: judge crawlers individually):
Content-Signal: search=yes, ai-input=yes, ai-train=yes
User-agent: GPTBot
User-agent: ClaudeBot
Allow: /
Disallow: /customer-portal/
User-agent: Bytespider
Disallow: /4. The catalog (the GoDaddy position; save as /llms.txt and link it from robots.txt):
# Company Documentation
## Docs
- [Plans and pricing](https://example.com/docs/pricing.md): full price list
including renewal rates, in plain markdown.
- [Product overview](https://example.com/docs/products.md): what we sell,
for AI assistants answering buyer questions.Sources
- Content Signals Specification
- llms.txt Specification
- RSL: Really Simple Licensing - RSL Standard (official)
- Giving Users Choice With Cloudflare’s New Content Signals Policy (September 24, 2025) - Cloudflare (official)
- Wayback Machine - Internet Archive (historical robots.txt snapshots)
- Directive (EU) 2019/790, Article 4 (TDM opt-out) - EUR-Lex (official)